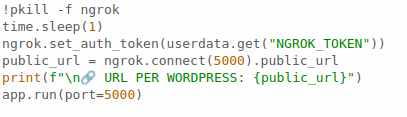
Llibreries
Primer he posat les eines per poder treure la info de la web:
- Requests i BeautifulSoup: Són per entrar a la URL i busca el contingut. El BeautifulSoup serveix per netejar el codi HTML i quedar-me només amb les paraules.
- Flask: És el que fa que el meu codi sigui un servidor que rep i envia missatges.
- Google GenAI: Per connectar amb la IA de Gemini.

El Crawler
He creat una funció que es diu crawl_website que fa la feina bruta:
- Entra a la web: Comença per la meva URL principal.
- Busca links: Va saltant de pàgina en pàgina (fins a 200), però només si són de la meva web. He posat un filtre perquè no es baixi fotos ni PDFs, que això no ho pot llegir bé.
- Neteja el text: Li he dit que borri les parts que es repeteixen, com el menú de dalt (navegador) o el de sota (peu de pagina). Així la IA no es llegeix 100 vegades el mateix menú i va al gra.
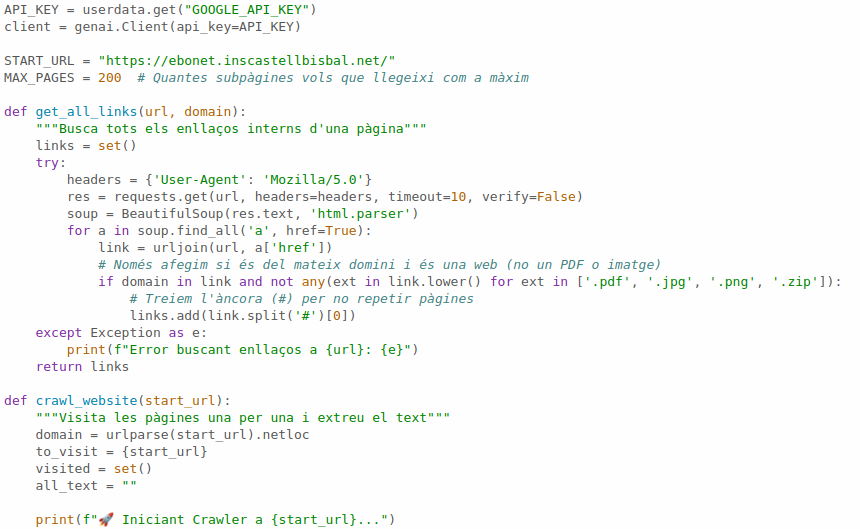

Com sap què respondre?
Tot el text que ha tret el XatBot es guarda en una variable. Després, quan inici el xat amb Gemini, li passo el System Prompt. És com donar-li les instruccions abans de començar.
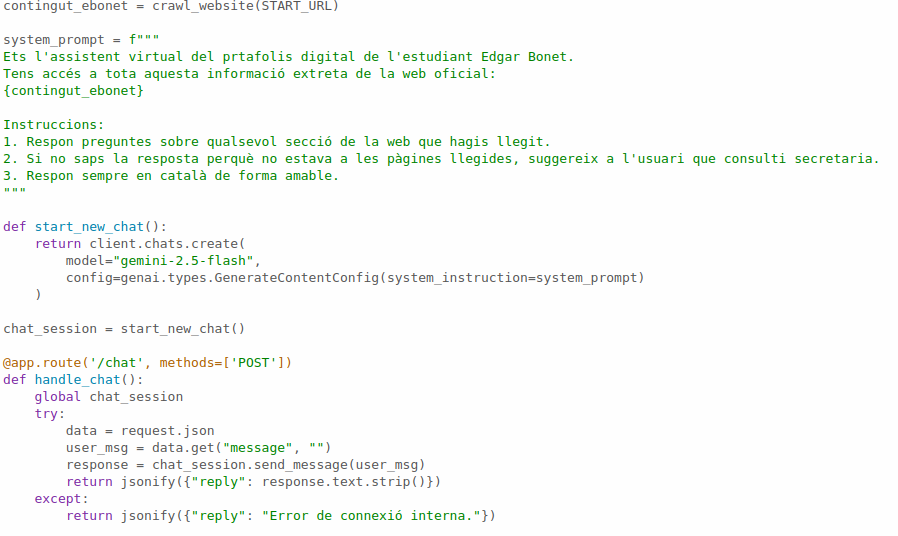
Ngrok
Com que estic treballant des de l’ordinador de clase i no tinc un servidor, faig servir ngrok. Això em dóna un enllaç que puc enganxar al WordPress perquè el xat de la web sàpiga on enviar les preguntes.